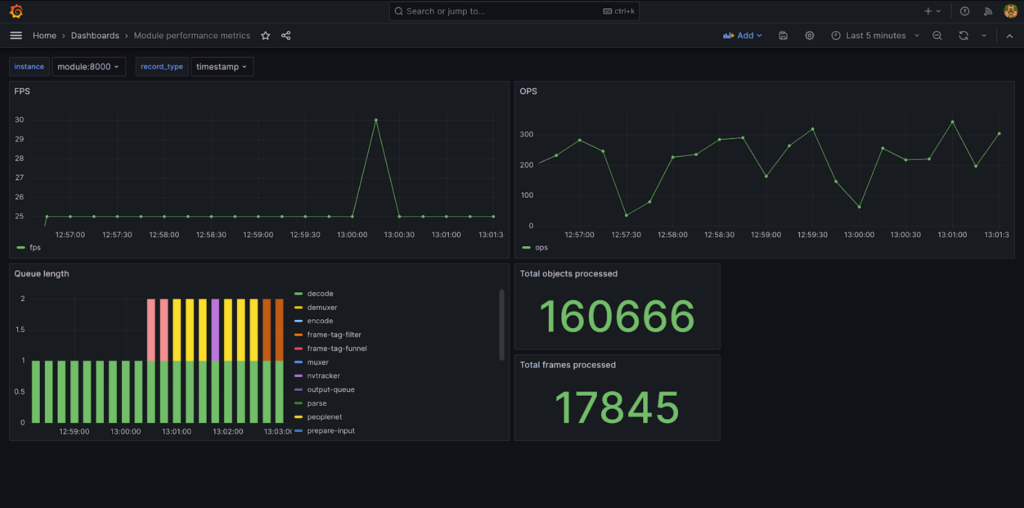
NVIDIA DeepStream SDK is a game-changer technology for deep neural network inference in computer vision served with NVIDIA hardware. The optimized architecture accounts for the specifics of NVIDIA accelerators and edge devices, making pipelines work blazingly fast. The core of the technology is TensorRT, which consists of two major parts: the model optimizer, transforming the model into an “engine” heavily optimized for particular hardware, and the inference library, allowing for rapidly fast inference.
Another DeepStream’s killer feature is connected with the CUDA data processing model: computations are carried on with SIMD operations over the data in a separate GPU memory. The advantage is that the GPU memory is heavily optimized for such operations, but you need to pay for it by uploading the data to the GPU and downloading the results. It can be a costly process involving delays, PCI-E bus saturation, and CPU and GPU idling. In the ideal situation, you upload a moderate amount of data to the GPU, handle it intensively, and download a moderate amount of results from the GPU at the end of the processing. DeepStream is optimized and provides developers with tools for implementing such processing efficiently.
So why do developers hesitate to use DeepStream in their computer vision endeavors? There are reasons for that we will discuss in further sections, and find out how to overcome them.
Continue reading Why Choose Savant Instead Of DeepStream For High-Performance Computer Vision