Transformer models become gradually more popular in computer vision. Even a couple of years ago, nobody broadly used transformers for computer vision. However, transformers have significantly changed the landscape of sophisticated deep learning solutions, primarily in natural language processing and generative AI.
DETR is a groundbreaking approach in object detection that applies the Transformer architecture, traditionally used in natural language processing, to computer vision tasks. This model simplifies the standard object detection pipeline by eliminating the need for many hand-designed components. RT-DETR is a model based on the paper available by the link.
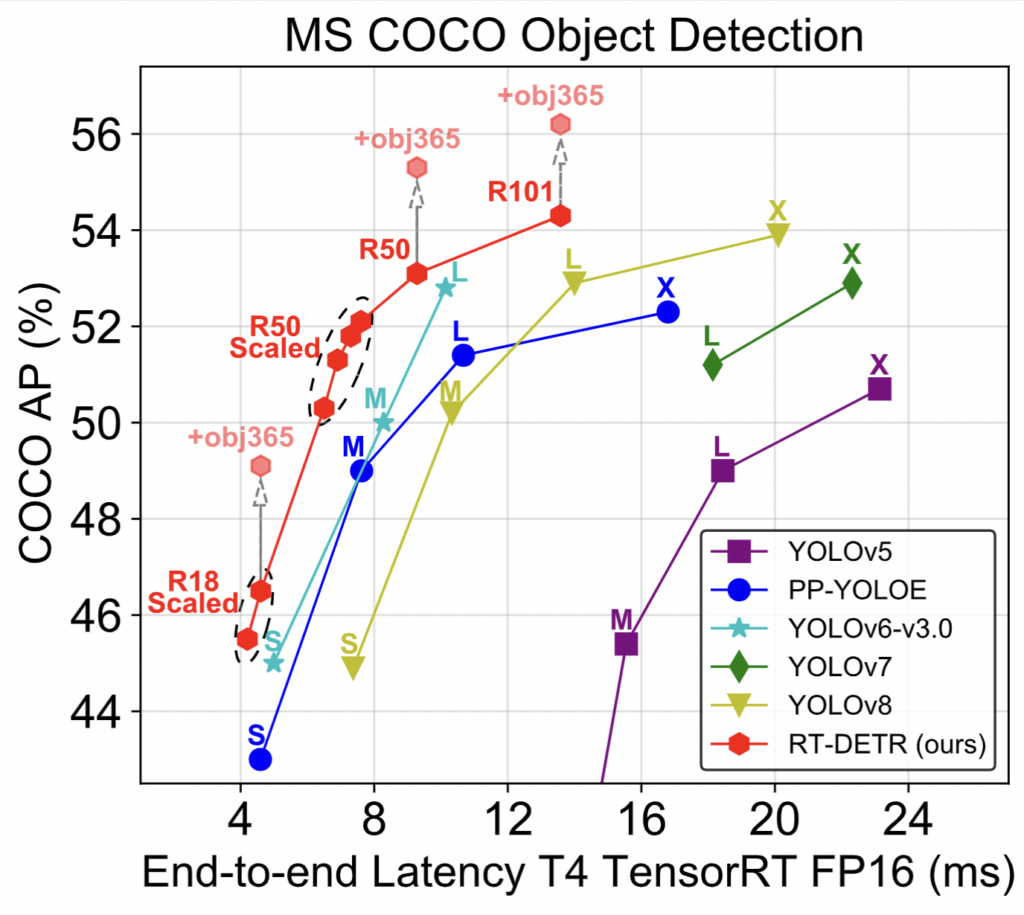
According to the model’s authors, it beats YOLOV8 in precision and performance. We at Savant believe there is a ‘no one size fits all’ solution, and computer vision requires mixing and matching various approaches for better results. Thus, a new model with outstanding performance is worth looking at.
Several days ago, a Savant user asked us if Savant is compatible with RT-DETR. We usually answer that if the model can be compiled with TensorRT to the engine, it must typically work in Savant. The user tried deploying the model and met a problem related to non-typical confidence values returned by the model implementation from the well-known GitHub repository DeepStream-Yolo.
During the investigation, we created a sample demonstrating using RT-DETR R50 FP16 with Savant. The model can deliver 150 FPS on a dGPU like NVIDIA Quadro RTX4000 and 24 FPS on Jetson Orin Nano 8GB (with jetson_clocks).
However, in our case, we did not see that RT-DETR works faster than YOLOV8M (254 FPS for YOLOV8 vs 150 FPS for RT-DETR R50); the model still is very promising because it is based on a new, more natural approach that already demonstrated unparalleled performance in the field of natural language processing.
The sample showing the use of RT-DETR with Savant is available by the link.