
TensorRT is a high-performance deep learning inference optimizer and runtime library developed by NVIDIA. It’s specifically designed for production environments and optimized for NVIDIA GPUs. The primary goal of TensorRT is to accelerate deep learning inference, which is the process of using a trained neural network model to make predictions based on new data.
TensorRT compiles models from native formats like PyTorch, TensorFlow, or ONNX into a highly optimized engine specific to the GPU where such a compilation happens. After the engine file is built, it can be used across the GPU family, e.g., Turing or Ampere, but ideally, it is worth compiling the engine for a specific GPU. The same applies to Nvidia Jetson devices.
In addition to the device family, TensorRT can also use other configuration parameters like batch size or precision when building the desired engine.
The compilation is a prolonged process, taking many minutes to complete; for example, YOLOV8 compilation may require 10-20 minutes, even on the most capable hardware. It heavily depends on the single-core performance of CPU and GPU RAM available. Compilation is especially painful when executed on Nvidia Jetson hardware. Such a compute-intensive process may cause edge CPU/GPU throttling and even crash.
Thus, it is beneficial to implement the mechanism checking the presence of the usable cached engine file before compiling the model unconditionally. If the engine is in place, the software can load it to save time.
Another side of TensorRT is deep learning inference. Optimized engines evaluated with TensorRT much faster than the same models with CUDA or OpenCL on the same hardware. According to Nvidia, TensorRT can give you up to 6 times faster inference than regular CUDA-based inference. In our practice, we registered a 2-3 times speed increase, even for FP16 precision, without switching to INT8.
However, in rare cases, TensorRT is not applicable. Let us discuss three such cases:
- Non-deterministic generation. TensorRT generates a slightly different engine every time it compiles. So, if you must have a deterministic process when building the model, it will not work for you. The inference is deterministic if the same data are fed to the same engine.
- Unsupported layers. TensorRT does not support particular DNN layers. To overcome the limitation, you can change the model architecture to exclude them.
- Your software does not support TensorRT. Sometimes, constraints prevent you from using it, and you must use suboptimal technology.
Technologies to Serve CUDA/TensorRT Inference Pipelines Efficiently
Using CUDA-based or TensorRT inference to get the best-in-class performance is insufficient. The NVIDIA hardware has a separate memory and requires data to be allocated in it before it can be handled (the situation is slightly different with Nvidia Jetson devices because they have shared memory, but the API assumes that we have CPU-allocated and GPU-allocated RAM).
Thus, you must upload the inference input tensors to the GPU and download inference results from the GPU to CPU memory. This costs a lot, so the software must be optimized for such processing. It changes the landscape significantly because there are few frameworks implementing it efficiently.
DeepStream SDK
As the technology vendor, NVIDIA created DeepStream, a low-level SDK helping build such optimizing pipelines on GStreamer. With DeepStream, it is possible to implement the pipeline that handles all the data, starting from the video decoding and ending with video encoding in GPU, mostly without CPU-bound processing.
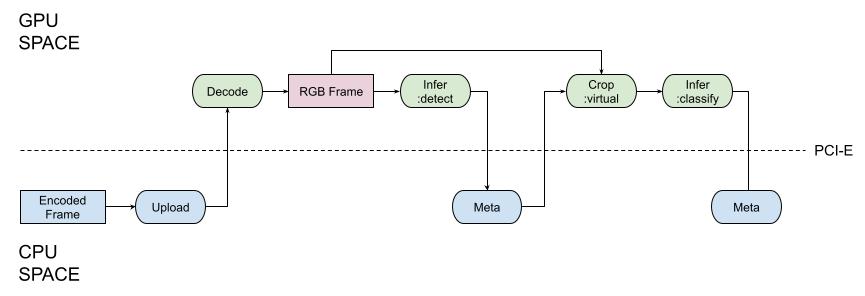
However, it is not easy because DeepStream is a steep and low-level technology. We, in Savant, democratize DeepStream by making it affordable for every deep learning engineer.
When to use. Streaming computer vision and video analytics.
Savant Framework
Savant is an open-source, high-level framework for building real-time, streaming, highly efficient multimedia AI applications on the Nvidia stack. It helps develop dynamic, fault-tolerant inference pipelines that utilize the best Nvidia data center and edge approaches.
Savant is built on DeepStream and provides a high-level abstraction layer for building inference pipelines. It is designed to be easy to use, flexible, and scalable. It is an excellent choice for building intelligent computer vision and video analytics applications for cities, retail, manufacturing, and more.
Democratizing DeepStream
Read the article on why to choose Savant instead of DeepStream.
When to use. Streaming computer vision and video analytics.
Triton
Another technology that allows serving TensorRT models efficiently is Triton; Nvidia also develops it but focuses on gRPC communication between the client and the inference server. Thus, it is suboptimal and inefficient for streaming computer vision but can be used with separate images or LLM models.
When to use. Ad-hoc RESTful inference when inference latency is not critical.
Torch-TensorRT
PyTorch also has TensorRT integration. However, it does not establish the architecture for the end-to-end functionality reflecting the picture portrayed above. Torch provides many primitives helping to build pipelines using the best practices with PyTorch.
When to use. You need to stick to PyTorch.
Pure TensorRT
TensorRT is available as a C++ or Python library without additional dependencies. If you feel capable of writing low-level code and have CUDA skills, you can use it natively. Accessing vanilla TensorRT inference from your OpenCV-CUDA-enabled application can be beneficial to avoid additional dependencies. Python API is also available.