When estimating the object’s pose, you usually deal with keypoint detection. It can met in various situations like facial recognition to align the face based on pose estimation or action recognition to estimate the actions and analyze them.
Keypoint models are used in:
- Motion Analysis: In sports and medical fields, analyzing how a person moves can provide insights into performance or physical conditions.
- Activity Recognition: By understanding the pose of a person, algorithms can determine what activity they are performing, which is helpful in surveillance, human-computer interaction, and entertainment.
- Augmented Reality: Keypoint detection can help in overlaying digital content onto people in real time, enhancing AR experiences.
- Animation: In the film and gaming industries, keypoint detection can be used for motion capture to animate characters based on actual human movements.
Person keypoint detection is a dynamic area of research and development in computer vision, with ongoing improvements in algorithms, training techniques, and computational efficiency. It is a foundational technology for many systems that require an understanding of human form and activity.
Computer vision pipelines implement a perception layer and are usually responsible for building a digital model representing observable objects in a virtual world. So, usually, they pay more attention to the detection of keypoints rather than analyzing the actions.
The task of action analysis is typically solved using CEP (complex event processing) systems, which are linked with actual computer vision pipelines and are fed with virtual objects produced by them. Data analysis systems such as Apache Flink or Apache Spark provide tools (Flink, Spark) for CEP, and we encourage implementing actual action recognition with them rather than directly in a computer vision pipeline.
What are Keypoints?
In object detection, a keypoint is a specific, detectable point on an object that represents a notable feature, typically because it stands out due to its texture, color, or the underlying shape. Keypoints are used to capture the geometry and stance of objects, and they are often parts of the object that can be consistently identified across different images, such as corners, edges, or distinctive texture patterns.
For example, in the case of detecting a car in an image, keypoints might be located at the corners of the headlights, the center of the wheels, or the tip of the side mirrors. These points help understand the position and orientation of the car, and they can be used to match the car across different images or to track its movement.
In deep learning-based object detection systems, keypoints are often automatically learned from training data. The neural network is trained on many examples of objects and their keypoints, and it learns to predict the locations of these keypoints on new, unseen images. This is particularly useful in applications like human pose estimation, where keypoints can correspond to joints or significant body parts, and the pattern of these keypoints can be used to detect and recognize human figures and their postures within images.
In the context of object detection and action recognition, keypoints have specific roles that are crucial to the performance and accuracy of algorithms.
In object detection, keypoints are part of the feature set that describes the objects of interest. Here is how they are used:
- Feature Representation: Keypoints create a sparse representation of an object. For instance, the corners and edges of an object can serve as keypoints that uniquely identify and describe the shape and pose of the object.
- Part-based Models: Some object detection frameworks, like Deformable Part Models (DPM), use keypoints to model object parts. The relative positions of these keypoints can then be used to detect objects even when they are partially occluded or when the viewpoint changes.
For action recognition, keypoints are primarily used to capture the motion and posture of humans or other subjects in a sequence of frames. Here’s how they function:
- Pose Estimation: Keypoints identify human joints in images or video frames. By tracking the movement of these keypoints over time, algorithms can recognize specific actions or gestures.
- Temporal Feature Extraction: In video sequences, the movement of keypoints across frames can be analyzed to extract features that describe temporal patterns. These patterns are essential for recognizing actions.
- 3D Reconstruction: For more advanced action recognition, 3D keypoints can be reconstructed from 2D images to understand the action in three-dimensional space, which provides more context and accuracy in recognition tasks.
Deep learning models, especially Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have been used extensively for object detection and action recognition. In recent years, architectures like the Transformer, initially designed for natural language processing tasks, have also been adapted for computer vision applications, including those involving keypoints.
For example, in action recognition, a sequence of images can be fed into a CNN to extract feature maps, and the temporal dynamics can be captured using an RNN or 3D CNNs. Keypoint detection can be integrated into this pipeline to provide a structured understanding of the pose and movement, which is then used by the network to classify the action.
Popular Keypoint Models in 2023
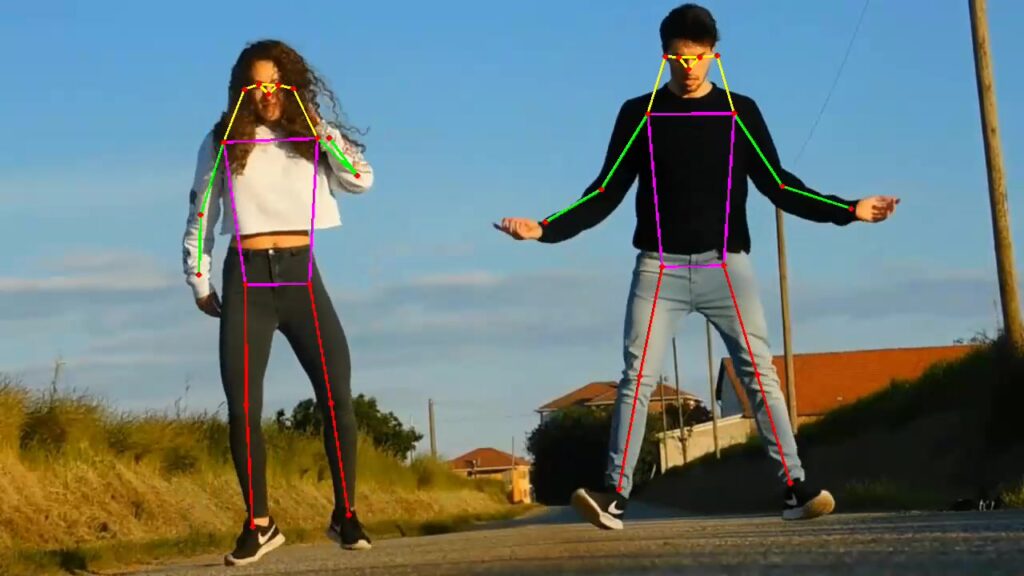
YOLOV8 represents a family of fast, high-accuracy models used for various popular tasks like object detection and segmentation, and there are models for keypoints prediction, too. We successfully used two of them: the face landmark model and the body pose prediction model.
Both models work pretty nicely, allowing the implementation of high-quality real-time pipelines working on the edge and in the data center. The facial landmark model is usually not recognized as a full-featured keypoint model (because landmarks serve an auxiliary function related to facial alignment); however, the body pose prediction model can be used for solving various action recognition tasks.
Users can train their keypoint models with YOLOV8 to implement solutions for their domains.
To help users utilize YOLOV8 keypoint models in Savant, we implemented a sample demonstrating how to work with human body keypoints. The demo video, showing its operation, is represented below:
Sample Structure
You can find it in the Savant GitHub repository: https://github.com/insight-platform/Savant/tree/develop/samples/keypoint_detection.
It is very simple by nature; processing elements deserving particular attention are:
- Model postprocessor, extracting keypoints from the output tensor;
- Draw function, which can guide you through the semantics of every keypoint.
Performance
As we mentioned earlier, the YOLOV8 family represents high-performance, high-accuracy models. Our measurements for the implemented demo show the following numbers (including overlay functionality, which also influences):
- 178 FPS on Nvidia A4000;
- 56 FPS on Jetson NX;
- 67 FPS on Jetson Orin Nano.
Don’t forget to subscribe to our X to receive updates on Savant. Also, we have Discord, where we help users.
To know more about Savant, read our article: Ten reasons to consider Savant for your computer vision project.