
This article answers the question of why you may find it beneficial to use Savant instead of DeepStream, OpenVino, PyTorch, or OpenCV in your next computer vision project. It is not an easy question, because computer vision is a tough field with many caveats and difficulties. You start with finding a way to make certain things doable from the quality point of view, but later you also need to serve the solution commercially efficiently, processing data in real-time rather than pathetic 2 FPS on hardware worth like a Boeing wing.
The latter task may require additional knowledge and technologies which introduces a terra incognita for a deep learning professional. In such an unfamiliar land further project development may involve new risks, that may be, initially unidentified. Acting reactively, you may start going the wrong way, by trying to get the desired results with inappropriate technology.
A real-life story
Our customer used PyTorch to serve video-inference. The system was able to deliver a very moderate performance because of the pipeline architecture. The developer who worked on the pipeline did not have enough knowledge and tooling to investiagate that the problem was not in the deployed models performance, but with the overall pipeline inefficiency connected with CPU-GPU memory exchange.
When the same pipeline (with the same models) was implemented with the use of proper technology, it demonstrated the tenfold performance increase.
So, what is a proper technology? It is a product optimized for a specified hardware. Please, hear that right: inference, not training. It is a common mistake to think that the same technology can do both. In the vast majority of situations, it is not true. Especially, it is not true for computer vision pipelines related to high-performance video processing, and there are reasons.
Computer Vision Pipelines Stay Aside From Other Model Serving Pipelines
… or why you may be cooking them in the wrong way.
Video analytics pipelines have features that make them unique:
- real-time processing required (30 FPS per source, multiple sources at once);
- multiple models are used together to produce the desired result, e.g. 1-2 detection models, 2-3 classification models, and ReID models;
- a vast number of models work very fast: ResNet-50 can reach 5000 FPS on modern hardware (Nvidia GPUs);
- computer vision-optimized hardware exists (Nvidia dGPUs and Jetson devices, Edge NPUs like Hailo, Intel Movidius, Google Coral, etc).
- compressed video stream often takes magnitude times less space than uncompressed; e.g. 1 second @ 30FPS for FullHD RGB frames (1920x1080x3) requires about 180MB RAM. However, the same H264-encoded frames require only 2MB and even less when HEVC is used;
The above-mentioned traits make computer vision pipelines special. The last point is a real game-changer. Just think of it: uploading the stream to GPU or downloading it may differ 90 times from the bandwidth utilization point of view depending on how it is implemented.
Compare this number with the theoretical performance of ResNet-50 and you will discover more certain unpleasant numbers:
- ResNet-50 handles 166 streams on a modern GPU;
- Uploading 166 streams uncompressed requires an enormous 30GB/sec which is definitely a blocker:
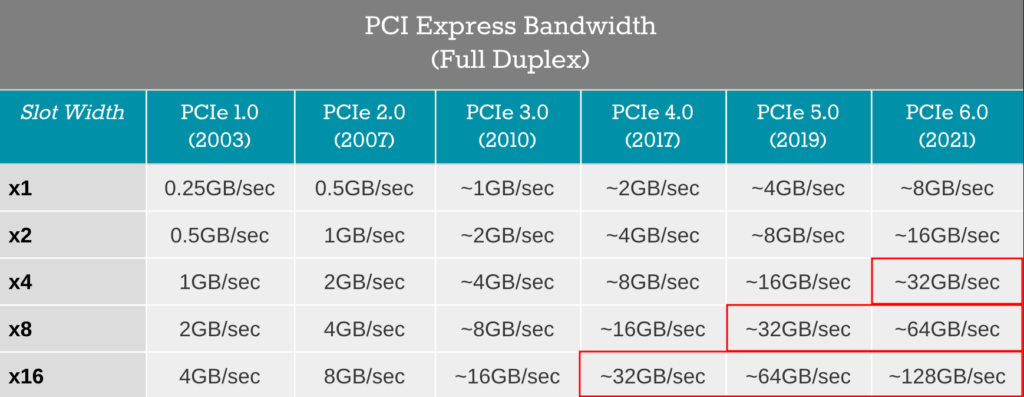
So, working with uncompressed streams is a completely unwise idea, when implementing real-life high-performance computer vision pipelines: your GPU can do more, but it will end up waiting for the data available. The other side of the system is also unhappy because the CPU spends a lot of resources to decode streams before sending their frames to the GPU.
So, the approach of decoding video on a CPU before sending it to a GPU for inference is usually a bad idea (well, if you run heavyweight GAN resulting in 2 FPS, then you don’t really care).
What About Edge?
Many edge devices currently have NPUs allowing inferencing many models like YOLO, and they do not tackle with such a problem expressed before. However, they have another problems related to NPU support in the modern frameworks and require very niche knowledge to craft a properly functioning computer vision
The Nvidia Jetson device family also have unified memory accessible from both CPU and GPU making them more efficient for RAW streams processing (e.g. if you deal with GigE Vision cams).
What If I Process JPEG/MJPEG?
The same applies to them too. Uncompressed images weigh 5 times more than compressed, considering that the factor may be less than for video, but it is still significant. Thus, when you pass your Numpy array to CUDA-enabled inference in PyTorch you obviously utilize much more PCI-E bandwidth than required.
The Solution
The trick is to use the right solution optimized for the hardware. For example, if you stick to Intel hardware only, use OpenVino SDK. If you stick to Nvidia, you need to use the technology optimized for Nvidia hardware which is basically DeepStream SDK.
However, that is not that easy, there is always a trade: using optimized technologies requires additional knowledge and understanding of how the underlying architecture works. Specifically, for the two above-mentioned SDKs you encounter a new programming model based on GStreamer – an open-source framework for media processing; and it definitely will make you cry 😭. OpenVino’s DL Streamer, Nvidia’s DeepStream SDK, and AMD’s VVAS are all based on GStreamer and do not look like an old good PyTorch or OpenCV programs.
GStreamer’s processing model is based on moving the data and signals through the pipeline and processing them with installed callbacks and custom plugins.
At this point, you might start to suspect something. For example, why do those hardware vendors not use something familiar and less complicated? Definitely, there is a reason: GStreamer is the only ready-to-use extensible software having an architecture precisely representing how things work internally.
As for today, the weapon of choice is very limited:
- Intel doesn’t have competitive AI accelerators, and CPUs are not competitive from the price/performance point of view;
- AMD VVAS works on Xilinx hardware like Alveo V70 and is pretty immature, considering its use by an average user without strong technical guidance from AMD;
- NVIDIA is the only solution providing mature technology, a broad line of hardware for both core and edge, and compatibility between hardware generations.
Considering the above-mentioned facts, most likely you will end up with NVIDIA hardware and DeepStream SDK as a technology allowing you to utilize NVIDIA hardware in full.
What About Savant Framework
Savant is a high-level framework on Nvidia DeepStream. Our mission is to make the best Nvidia technologies affordable to deep learning and machine learning engineers without making them cry. When you use Savant, you use DeepStream under the hood, but without the need to understand GStreamer, and C++ coding, and with many batteries included out-of-the-box.
To this part, you should clearly have understood why vanilla PyTorch or OpenCV are not the right technologies for video analytical pipelines, but with Savant, they could be used in the optimized way! In the next sections, I will disclose and explain why consider Savant instead of low-level DeepStream in your next computer vision project.
Savant is open-source and is published under the Apache 2.0 license, making it possible to use the technology in both open-source and commercial projects.
Savant is a framework, not a library. It means that it defines the topology, architecture, and behavior – you only need to fill it with functionality to achieve the desired behavior, but even an empty pipeline is functional.
The Foundation Of Performance
Let us begin with establishing of the foundation why DeepStream SDK is fast and why you cannot easily reproduce its performance with just Python, OpenCV, PyTorch, etc. To start with, I will show you models demonstrating the difference between naive and optimized approaches.
Data Flow Model
Let us begin with a naive data flow model, you will likely implement using an OpenCV or PyTorch tutorial found on PyImageSearch, and this is definitely not how it must be.
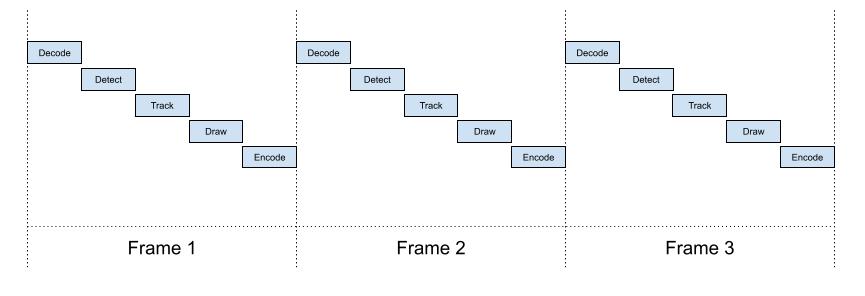
You can easily find that most blocks can work in parallel, so the optimized model would be like this:
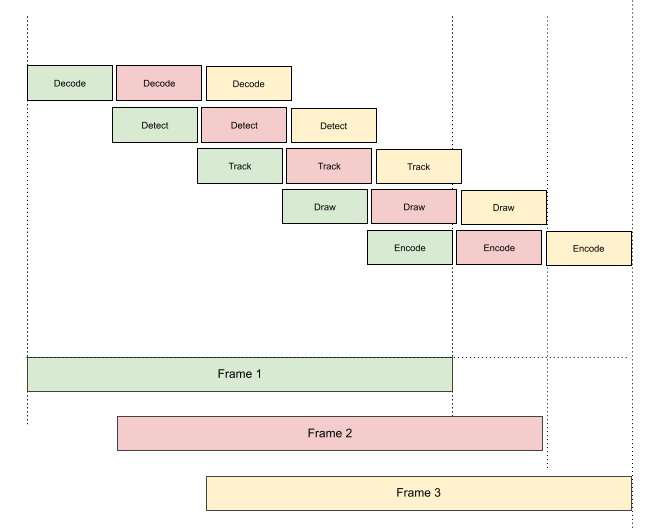
And unfortunately, it is not what easily can be done in Python, even with threading. As you can see this model allows utilizing every block as soon as it is spare, which radically differs from the approach used in the naive pipeline when the pipeline cannot handle the next element until the previous element is completely processed.
This is what GStreamer brings on board: whenever the resource is spare it pulls the next element out of the queue and works with it. Let us discuss what it gives to a computer vision pipeline.
Discuss the advantage of the optimized data flow model with decoding and encoding; these operations are executed on NVDEC and NVENC: dedicated hardware units. They do not share their resources with other computing blocks, so the optimized workflow uses them as soon as possible; the previous frame leaves, and the next frame comes. Such situations occur in every step of the pipeline, which helps fill the idle periods and utilize spare resources whenever it is possible. As a result, it leads to greater performance because of better hardware utilization. But it is only part of the whole picture: the hardware architecture also influences greatly.
Memory Motion Model
When you develop your code you always initiate data motion between RAM and CPU, and in the accelerated video analytics scenario, GPU. Again, let us start with a naive PyImageSearch-y approach.
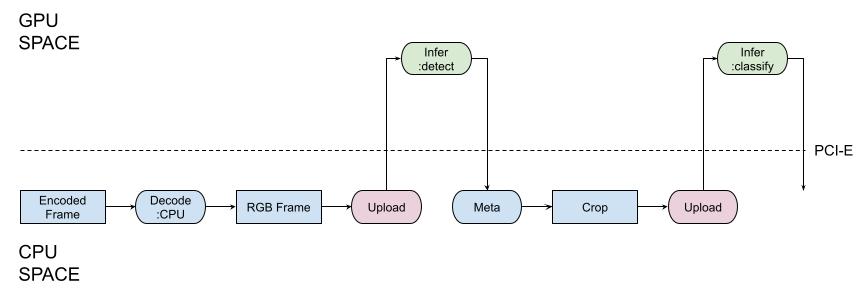
You can see multiple uploads moving large RAW images between CPU and GPU every time you want to run CUDA-enabled inferring. To say more, when the inference works, the code operating on the CPU just waits for its completion (the part of the previous naive model). Instead, the optimized model looks as portrayed in the next picture:
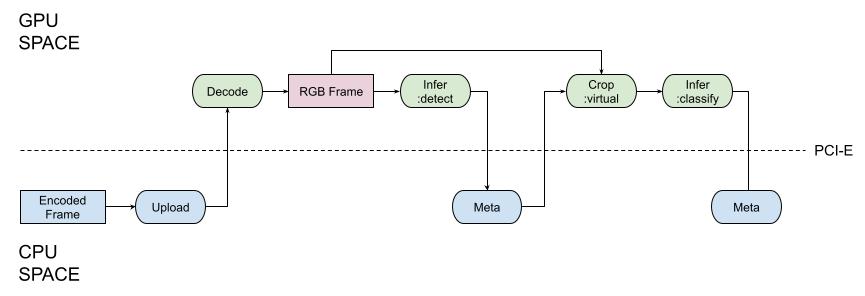
As you can see, the video frame is uploaded to GPU in the encoded format (compact size, less bus utilization), and the rest of the operations except those that process inference results like detected boxes, feature vectors, and masks are executed with GPU. The important thing is that as the GPU is a separate computing device it can work in parallel with the CPU (see the optimized data flow model).
Now, we are good to go straight to Savant as a technology simplifying the use of DeepStream SDK, which in turn embodies the above-discussed concepts.
1. Performance
Savant is based on DeepStream and is almost as fast as it. It is definitely way faster than any straightforwardly implemented code with OpenCV and PyTorch without diving into hardcore C++ development which in the end would result in a solution similar to DeepStream.
However, Savant is not as fast as a highly customized solution implemented on DeepStream or underlying technologies. The reason for that is that Savant is not a zero-cost abstraction: it is a framework handling various situations and providing additional developer tools.
So if you are interested in squeezing the absolute maximum from the hardware, it may be worth implementing a custom code utilizing Nvidia low-level libraries. If you are okay with, say, 80-90% of the max, you can go with Savant. If you are okay with 10% of the max – go with PyTorch and OpenCV 🙂
2. Convergence (Edge, Workstation, Data Center)
Savant pipelines work without changes on Jetson devices, desktop GPUs (GeForce), and Data-center GPUs (like T4, A10, etc) without the need for changes. It means you can develop on your GeForce-enabled GPU and deploy the pipeline either to an edge device or to high-performance data center hardware. Definitely, a less capable edge device will deliver less performance, but you don’t need to reimplement the pipeline.
To say more, Savant allows crafting hybrid pipelines partly evaluated on edge and partly in the data center on the most appropriate hardware. It gives developers ready-to-use tools to effortlessly implement such multi-step, hybrid solutions.
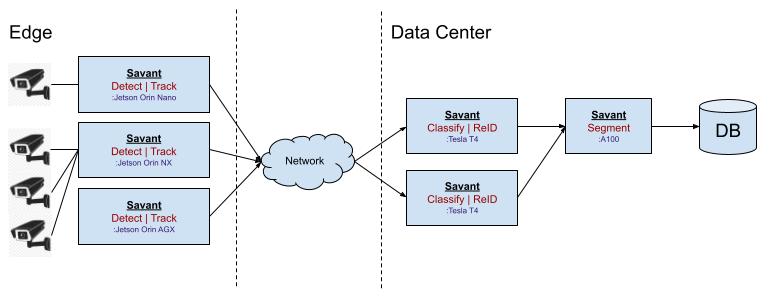
DeepStream. Vanilla DeepStream requires not only module adaptation between edge and data center platforms but also does not provide means to implement such hybrid pipelines. More on them you will know in the following sections.
3. Pythonic
Savant provides a developer Python-first API, allowing the use of a friendly environment and familiar tools for working with metadata, state, and Savant functions. When developing a pipeline, you can use NumPy, OpenCV-CUDA, Numba, and Cython to optimize resource-demanding operations and release GIL unleashing the power of threading in Python. When needed the developers may optimize Python code with other popular FFI instruments like C++ or Rust with PyO3 to overcome the bottlenecks.
When used PROPERLY, Python plays the role of the control-flow engine, in the meantime, internally, Savant uses high-performance C++/Rust primitives to handle resource-demanding operations, and DeepStream, which is also a C++ code.
Savant also comes with a utility library savant-rs, containing high-performance primitives and operations implemented in Rust.
DeepStream. Vanilla DeepStream provides only low-level bindings to GStreamer helping users access DeepStream-specific formats kept in GStreamer metadata.
4. API-first Solution With Ready-To-Use Interfaces
A Savant pipeline works as an API-enabled inference server. It uses a special streaming protocol based on ZeroMQ and Rkyv to communicate with the outer world. The protocol carries video and metadata, containing objects and arbitrary attributes. With the protocol one can easily communicate with the pipeline, injecting data and retrieving results. There is a Client SDK library, allowing you to do it with simple Pythonic API.
The protocol is highly extensible: you can encapsulate arbitrary data within it, including custom telemetry or IoT information, like GPS coordinates. These values are accessible from the pipeline code, helping implement communication with external systems.
Savant comes with plenty of data adapters, like USB-, RTSP-, file, Kafka, etc. These adapters also use the protocol to communicate with the pipeline. You can easily implement your own adapter based on the provided samples.
DeepStream. Vanilla DeepStream supports only sending metadata to external systems, but there is no out-of-the-box solution to inject custom metadata alongside with video in the pipeline.
Read more on how Savant’s protocol enables advanced data processing models.
5. Production-Readiness
Savant architecture is based on a containerized environment. Every pipeline and adapter are executed in separate containers communicating via the Savant protocol. It makes it easy to deploy them in the compose or K8s environment.
Savant supports OpenTelemetry out-of-the-box helping instrument the deployed code precisely with traces. The traces occur in adapters and transpire throughout all the communicating parts via the Savant protocol. The telemetry is delivered to Jaeger and can be analyzed when needed. Developers can add custom attributes and log records to telemetry spans.
Dynamic Etcd attributes are supported out-of-the-box. With Etcd developers can change the behavior for deployed pipelines without reloading.
DeepStream does not define the architecture, it is just a set of plugins for GStreamer. Developers need to build and design the end-to-end deployment by themselves.
6. Great Developer Tools
Savant is made by developers for developers. We strive to provide the tools to help you craft pipelines effortlessly. Let us briefly discuss what instruments you have when using Savant.
Develop In Docker from your PyCharm or VS Code. You can develop locally or on a remote device (for example, from your Notebook without GPU on Nvidia Jetson). You need zero configuration on your local machine because everything works inside Docker containers.
Client SDK. It helps easily communicate with the pipeline right from the IDE with Python. It also helps integrate pipelines with 3rd-party systems easily.
DevServer. This function enables the hot reload of the custom user code on change. Pipeline restart can take several seconds. The feature can be enabled optionally for development.
OpenTelemetry. With OpenTelemetry developers can collect valuable runtime information to profile the code either during development or in production. It helps to understand what is going on on a per-frame basis, by tracing its lifecycle from the moment of its occurrence till its end of life.
Read more on module development in the guide.
DeepStream. Vanilla DeepStream does not provide competitive tools for developers.
7. Simple 3rd-Party Integration
With the use of the adapters, ClientSDK, Savant protocol, and Etcd you can easily ingest video/image together with auxiliary information and implement data materializing in various storage engines like MongoDB or ClickHouse. Out-of-the-box, we provide Kafka/Redis bridge adapters allowing integration of Savant pipelines in the scalable enterprise infrastructure.
8. OpenCV CUDA Integration
We started the article with the picture portraying the properly implemented memory model, let us recall it:

To support the model, Savant provides developers with instruments allowing custom operations on GPU-allocated images with OpenCV CUDA: when needed you can access the frame with CUDA-enabled OpenCV functionality and implement transformations immediately in CUDA memory without downloading the frame to the CPU memory.
It is a killer feature of Savant. In Vanilla DeepStream you don’t have ready-to-use high-level instruments to work with GPU-allocated images.
9. Samples And Demos
In the repository, you will find a broad set of examples demonstrating almost any feature of Savant, including features discussed in the current article and various models like YOLO8 (detection, segmentation), and Nvidia PeopleNet. With them, we demonstrate how to solve real-life cases.
There are also utility samples demonstrating OpenTelemetry, Etcd, chained pipelines, data analysis with Grafana, and more. Many developers use samples as barebone pipelines for their real-life solutions.
10. Friendly And Helpful Developers
We maintain a healthy Discord community where you can ask any Savant-related questions and get answers quickly. Please join and don’t hesitate to share your ideas.
We also highly appreciate your insights and contribution.