
There are two types of computer vision applications around us: the first ones deliver rapidly fast, instant image or video processing to signal about critical situations like car accidents, people in danger zones, or serious outages in factories; others handle data on demand or in a delayed manner to deliver the knowledge at scale. Those two kinds have in common that they process video data, but their differences are too significant to ignore.
In the article, we briefly discuss the first class and focus mostly on the second group, and you will understand why very soon.
Real-Time Computer Vision
Read this before you begin…
Before you move further I highly recommend you reading the article discussing the problematics of real-time, near-real-time and non-real-time video analytical and computer vision pipelines in detail.
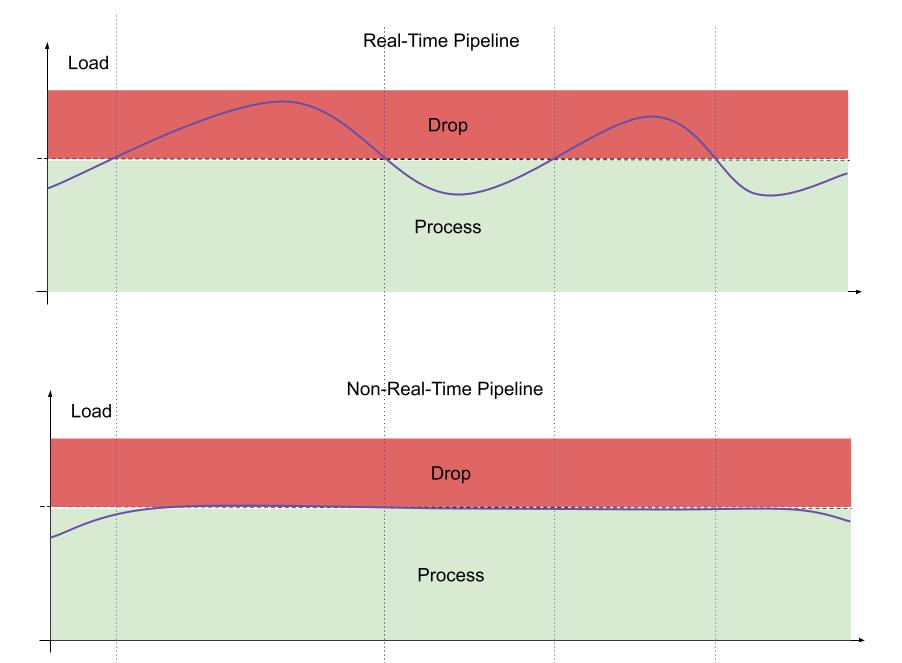
Let me begin with the first camp represented by real-time video processing. This group is characterized by low-load processing: to keep up with video streams, the pipeline must always have reserved capacity even in the most unexpected situations, to ensure that signals are delivered within the desired time span.
Such design is widely used in manufacturing, robotics, and safety systems when the lag of data delivery is harmful. Often, real-time video processing is deployed on edge devices, such as the Nvidia Jetson family, and operates in a disconnected mode without an always-available central management system.
Luckily, by default when somebody connects a USB cam or RTSP stream to an OpenCV, DeepStream, PyTorch, or Savant (you are reading the Savant blog after all 😊) they end up with a real-time pipeline processing data with low delay. The only trick is to implement and benchmark the pipeline properly, to handle the video data even in the hardest cases. We, at Savant, consider the real-time design simple from the architectural point but difficult to meet the constraints.
Read more on the topic in the above-mentioned article.
Non-Real-Time Scalable Computer Vision And Video Analytics
Now, let us move straight to the design of the systems handling large volumes of video in a non-real-time fashion. We, at Savant, love such systems because they have a very lean resource design, allowing maximizing the use of AI accelerators and growing out systems horizontally to hyper scale.
What is Savant Framework?
GitHub: https://github.com/insight-platform/Savant/
Savant is an open-source framework for building real-time and non-real-time, highly efficient video analytics and computer vision pipelines on the Nvidia stack. It helps to develop dynamic, fault-tolerant inference (model-serving) pipelines that utilize the best Nvidia approaches for data center and edge accelerators.
Savant is built on DeepStream and provides a high-level abstraction layer for building inference pipelines. It is designed to be easy to use, flexible, and scalable. It is a great choice for building smart CV and video analytics applications for cities, retail, manufacturing, and more.
Now, we can describe the traits of such non-real-time systems:
- They utilize compute resources (CPUs, GPUs) at their maximum capacity to optimize the volume of data processed per $.
- They strive to process the data as soon as possible, but there is no hard deadline.
- They scale well, allowing you to add video streams and processing hardware as you go.
- When the system experiences resource shortage or outage, the data are not lost, but buffered to be processed later.
- The same data can be processed multiple times if necessary.
- They deployed in data centers more often than on edge.
Video Ingestion Methods
There are two ways to ingest video data in non-real-time video analytical systems:
- files in a local file system, S3 or HDFS;
- streams (with messaging systems like Apache Kafka).
Depending on the purpose, every approach can be more or less desired. Let us highlight their pros and cons (this discussion is somewhat relative because in certain situations cons may become pros and vice versa).
Files
Pros: Easy to begin with at early stages.
- easy to use for a developer;
- few systems are required to serve video data (traditional filesystem, HDFS, or S3);
- simple on-demand processing implementation;
- better sharding capabilities even for a single source (based on file slicing);
Cons: Inconvenient at scale. Requires reinventing of the wheel to implement every aspect of processing.
- additional systems are required to bind data to metadata (based on PTS and video file unique URI, which may be inconvenient);
- ingestion ordering is not supported by traditional filesystems, HDFS, and S3 (creation time attributes and additional techniques based on naming can help);
- processing model is based on batching, not streaming.
To sum up, file-based ingestion is worth looking at and can be a handy and even preferred approach in many cases.
Storage-backed Streams
Pros: a scalable, production-ready solution without custom parts.
- easy to scale out the system as soon as necessary;
- control flow is provided by a streaming system;
- a natural approach typical for video playback;
- corresponding metadata can be associated with a particular video frame (in place or as a link);
- embedded data indexing;
Cons: Multiple moving parts make the learning curve steep and sophisticate the architecture.
- developers need to learn streaming platforms;
- requires additional tooling for developers to ingest video to a streaming system and access results;
- parallel processing of a particular stream may be difficult to implement;
- may require more infrastructure to maintain.
To sum up, stream-based ingestion is an industrial solution providing ready-to-use streaming and scaling models but may involve non-trivial design if the processing scenario is not supported out of the box.
Summary. It is incorrect to compare the two above-discussed approaches in terms like “good” or “bad”: system architects need to analyze the video processing scenarios to mix and match.
Video File Processing In Savant
Video file processing has been in Savant since the first version. The video file source adapter provides basic support for processing multiple files at once. It can be extended to monitor the local filesystem (Inotify) or S3 (bucket subscription) for new objects.
However, as we previously discussed, file-based data ingestion does not provide the infrastructure for control flow management and scaling. Thus, we did not develop more advanced video file-based adapters for Savant, because there is no solution fitting all needs.
Universal data ingestion
Savant pipelines do not depend on how you ingest data: one can develop with video files, next switch to RTSP or streaming system without pipeline modification; it makes it easy to develop locally and deploy into production environment when the pipeline is ready. Read more on Savant adapters in the documentation.
Video Stream Processing In Savant
The interesting thing about video files is that they still contain separate trivial packets organized with PTS and DTS timestamps to help the video decoder process them in the right order. Such “messages” can be extracted from the video file container (or from a live-stream container like RTP) and ingested individually to a messaging system along with the associated data contained in the container like codec information, FPS, PTS, DTS, keyframe information, and so on. On the consuming side, those data can be collected into a required format or ingested in the pipeline for processing.
The Savant framework video processing model is based on the above-discussed approach: we unpack video frames from supported video containers, repack them into the Savant custom protocol messages serving video data and arbitrary metadata, and send them via supported channels to and from pipelines. The process does not include video transcoding – data are sent intact.
The default messaging system in Savant is ZeroMQ: it is used by adapters to talk with the pipeline (the pipeline does not support other messaging systems). However, the adapters, similarly to the way they read and write files, can work with advanced messaging systems like Kafka to extend the transport beyond ZeroMQ.
The protocol allows passing video and metadata together in a single envelope or separately when the metadata message contains the link to the corresponding video message.
Such a model is beneficial because helps utilize different combinations of systems for metadata and video based on desired purposes and deduplicate video frames when needed by avoiding copying them when metadata are updated as it would be if the video messages were encapsulated in metadata.
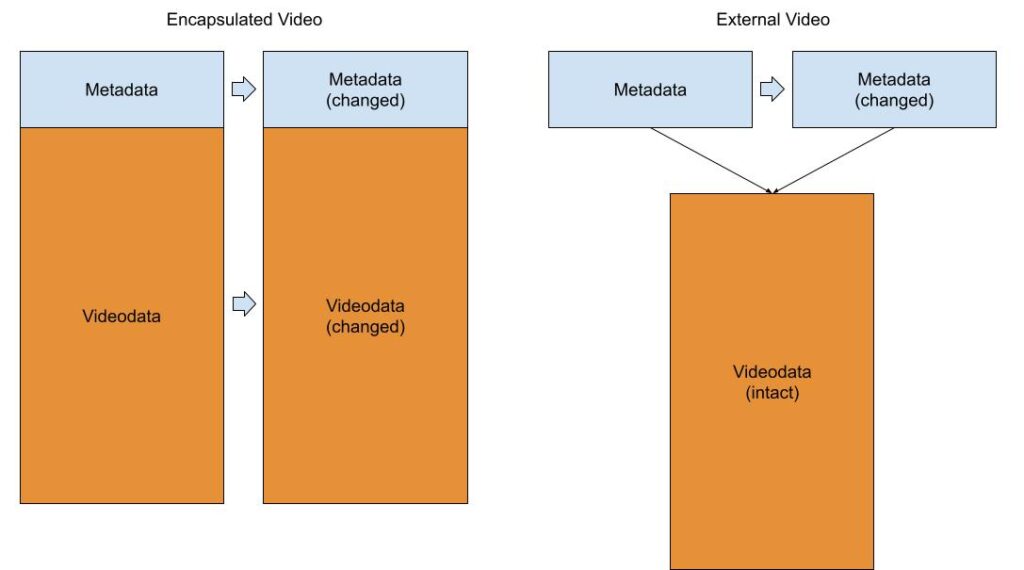
Video deduplication is a big idea for computer vision when messaging systems are used because it helps build highly efficient systems in scenarios when the same data is processed by multiple pipelines at scale.
The Place Of Apache Kafka In Scalable Video Processing Architecture
Kafka has several traits making it a great solution for implementing scalable stream-based video analytics and computer vision systems. Let us consider them in detail in the Savant context.
Scalability foundation. Savant uses a multiplexed processing model, which means that a single launched pipeline instance handles many streams at once. Such an approach maps perfectly to the model used by Kafka consumers when a topic processing is evenly distributed among the consumers based on Kafka partitions. It enables horizontal scaling by adding additional pipeline instances. The broker automatically determines the change in the number of consumers and rebalances the processing involving new pipelines. It may introduce additional problems related to state management, but, this is an application-level task.
High throughput. Kafka is well-known for its high throughput in both message number per second and MB per second. We may place metadata or metadata with video payload without restrictions.
Simple replay. When you need replay data you just command your consumers to start from the specified point (offset) or the timestamp. It also works in the situation when you need to process a certain part on demand, but do not want to process everything.
Reliable processing. Kafka supports the “at least once” semantics guaranteeing that all the data will be processed. In some bad cases, it may lead to a situation when certain messages will be processed twice – but it is usually not a problem for computer vision applications.
Fault-tolerance and recovery. Kafka automatically maintains replicas, replicates, and recovers the data when the infrastructure changes. With out-of-the-box utilities, you can replicate data to implement various storage conditions for hot and cold data.
Low delay when needed. When the system has enough processing capacity, Kafka can serve as a queue with subsecond latency. Often, it is more than enough even for systems that are designed to work in real-time but can switch to delayed processing when overwhelmed with data flow.
Economic efficiency. Kafka works perfectly on old good HDD drives which enable building economy systems to store large amounts of data, without the need for expensive SSD drives. The cheap drives do not restrict users from building reliable replicated systems required for production-grade systems.
Automatic backpressure. When a consumer reads from Kafka it operates in pulling mode, reading the amount of data it needs. There is no such a situation when data are dropped because consumers cannot read them (only if TTL is not configured).
Old data retention. Kafka topics support setting TTL: a mechanism enabling eviction for old data no longer needed. It matches naturally to how video analytical archives work, a user specifies the amount of time to keep a video.
Considering the above-mentioned features we believe that Kafka is an appropriate software for implementing video stream storage and ingestion in computer vision systems working in a non-real-time manner.
It is not a guide to Kafka, so we cannot dive deeper to explain the technology in greater detail. Wrapping up, Kafka streaming alone cannot provide the most efficient way of implementing multi-stage video analytics when video data remains intact: it does not provide an API to keep video frames aside of messages without duplicating them. Thus, a separate system is required to implement video deduplication.
Video Deduplication With a Key-Value Storage
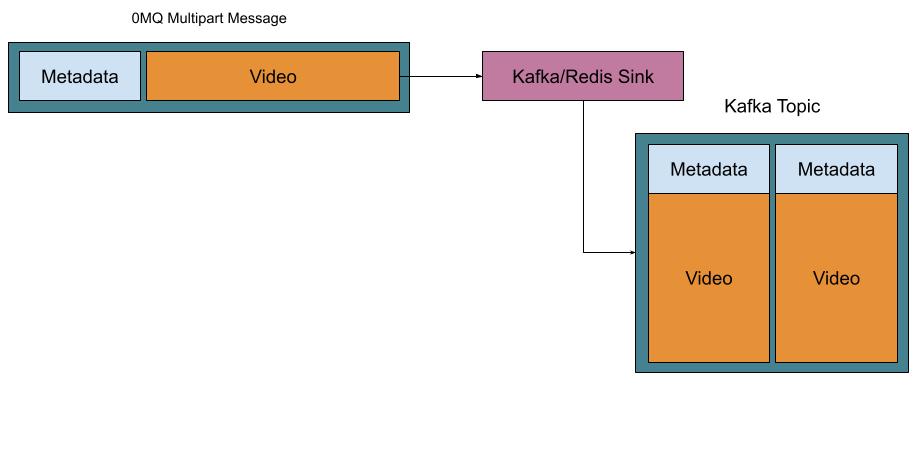
Let us recall the picture presented earlier.

Kafka, being deployed alone, supports the scheme portrayed on the left, while often we need a way to implement the model on the right. To support it, we usually want a key-value store with TTL supported (because Kafka supports TTL too and we need to match both systems). Most popular high-performance key-value solutions are based on the Redis protocol. So, if we pair Kafka with Redis we can implement the solution we really want.
Redis-compatible storages…
The original Redis is an in-memory solution. However, currently, there are plenty of databases compatible with Redis, allowing Redis clients to store the data not only in memory but also on disk, with replication, etc. One such key-value solution is KeyDB, but there are other players like Tidis, KVRocks, etc.
In Savant, we utilized the power of Kafka and a Redis-based key-value storage to implement an approach allowing the passing of video data through multi-stage non-real-time pipelines efficiently, with deduplication.
Kafka/Redis Adapters In Savant
Two adapters are implemented for the Kafka/Redis transport solution. The sink adapter connects the native Savant transport based on ZeroMQ with Kafka and Redis and works as an exporter. The source adapter works as an importer, connecting Kafka and Redis with the native ZeroMQ transport. Thus, you can use adapters, working with the native transport paired with Kafka/Redis adapters to export data or import them transparently.
The pipeline knows nothing about the external data motion architecture and is used as is.
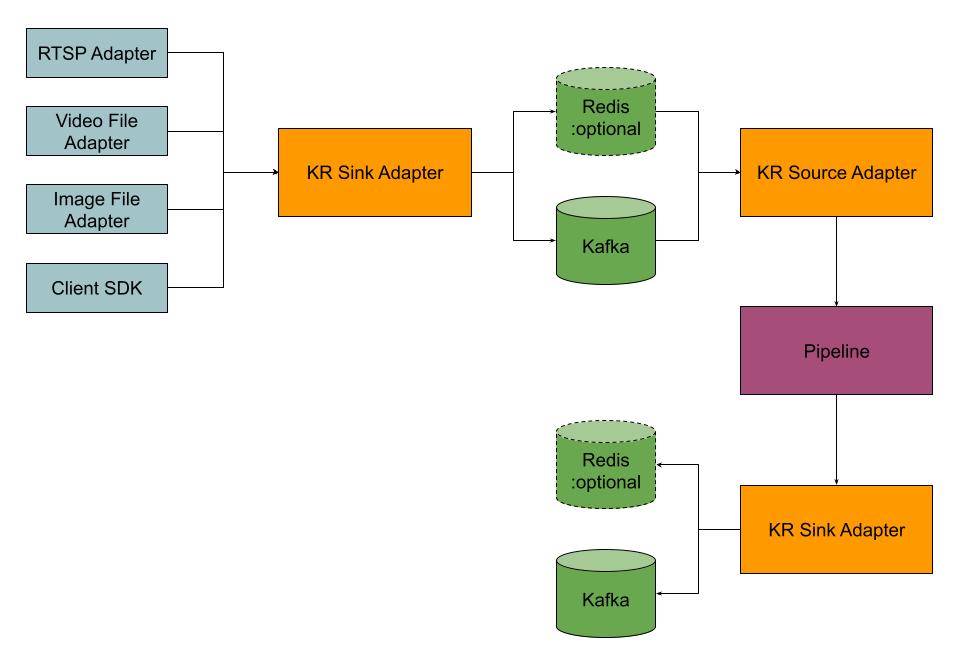
The implementation supports multiple topic partitions allowing building scalable solutions. When the video is processed in the pipeline in the pass-through fashion, and adapters are configured with the same Redis path, the deduplication takes place.
When both Kafka and Redis storages are configured, the sink adapter works as portrayed in the next image (the source does the opposite operation):
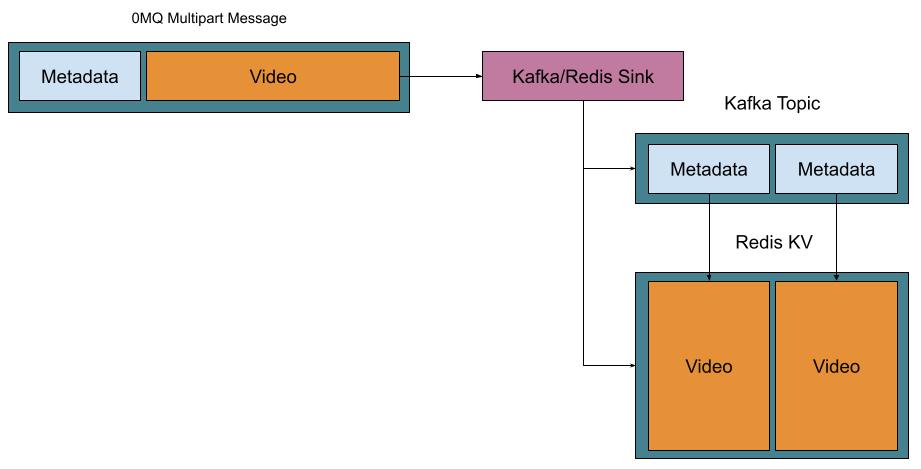
When only Kafka is configured, the relay operation looks as follows:
End-To-End Sample
The Savant repository contains an end-to-end demo showing how the Kafka/Redis adapters work.
Don’t forget to subscribe to our X to receive updates on Savant. Also, we have Discord, where we help users.